Chat GTP Experts - It is GPT.
Artificial Intelligence is taking over every aspect of the world. To be more specific, artificial intelligence is taking over the world. What is it? How does it work? What does it do? Time and time again, I see myself in situations where decision makers in companies want to push AI, speak from a position of knowledge while having no real insight or understanding as to what AI is, how it works, or how it can be beneficial. They just want it. They see it everywhere, and for fear of getting lost in the dust, they reiterate whatever 2-hour webinar they attended, or what some 5 minute Yahoo! article told them. Well, buckle up friends. My article is 6 minutes.
Let me break it down.
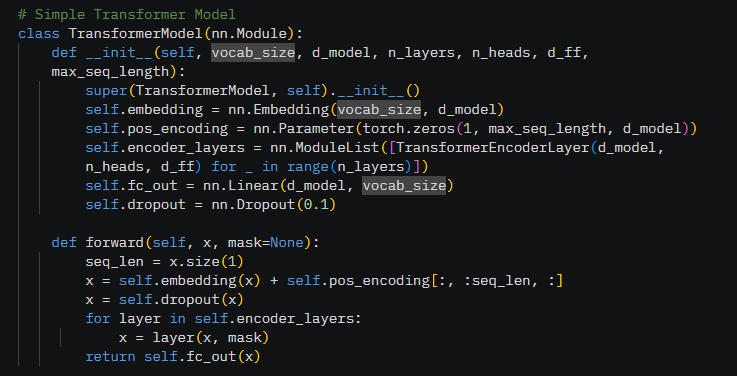
How does it work? I'll try to make this as simple as possible. Popular online conversational AI Models use a transformer-based neural network. Transformer models work by processing text using layers of interconnected nodes that are designed to understand context and relationships in language. The Encoder processes the input sequence (What you enter into the platform), and the Decoder processes the output sequence (What the platform returns as a response).
In short, the process begins with input, which is fed into the encoder. Self-attention allows the model to weigh the importance of different words in the input sequence, relative to each other, capturing context. Feed-forward gets a little tricky, it adds non-linearity and transforms the data. Let me explain. Imagine each word you input gets its own mini-brain process. This step takes the words current understanding (from the self-attention step) and tweaks it to make it smarter or more useful to the task. It's essentially putting each word through two quick filters. 1. expands the words information to explore more ideas, and the second one narrows it back down, keeping only the important stuff relative to the input and transforms the data based on patterns learned during model training. Think of it like seasoning food, the attention gives the base (how words connect), and the feed-forward steps add spices to make each word taste just right. It helps the model understand the words themselves while also providing context that's relevant to the input.
In short, the encoder focuses on understanding the input, while the decoder uses that understanding to produce the output. This structure enables Transformers to handle tasks like translation or text generation efficiently.
Pre-training in an LLM involves training the module on massive amounts of text where it learns to predict the next word in a sentence, or guess missing words. (Example: "Our shareholders are pushing AI in our ____" or "Our _____ are pushing AI in our company.") Pre-training LLMs is a key reason why data harvesting is valuable. LLMs rely on vast amounts of text data to learn language patterns, grammar, and contextual knowledge. The quality and quantity of this data which is harvested from various sources which directly impact the model's ability to generalize and perform well across tasks. More diverse and extensive datasets enable better prediction accuracy and richer understanding, making data harvesting essential for building effective and scalable LLMs. However, it also raises ethical and legal considerations, such as privacy and copyright, which are actively debated in the field.
The models are then fine tined with supervised learning from human feedback. The model is adjusted to align with human-like conversational behavior.
When you input a prompt, it's tokenized (broken into smaller pieces), and converted into embeddings and processed using a transformer model. Responses are then output, predicting the next token iteratively. Tokens per second (TPS) in LLMs refer to the rate at which the model can generate tokens during the inference. Primarily in the decoder phase of the transformer module. The speed, or TPS depend on factors like the model's size, hardware (GPU), and optimization. High TPS only means faster responses, and does not reflect a models accuracy. A technique called quantization in LLMs helps to reduce a models size and improve it's efficiency by lowering the precision of numerical values. Often by converting high-precision floating-point numbers to lower-precision formats like 8-bit integers. This reduces memory usage and speeds up computation, making the model faster and more suitable for devices with limited resources, such as on-device models, and locally hosted private models. It is worth noting that this can slightly affect accuracy, and models usually undergo post-training quantization.
Is my data secure?
Perhaps. Perhaps not.
Most free LLM platforms may store conversation data for training and improvement, unless they explicitly offer privacy options.
Does this mean your sensitive business information you enter into Chat-GPT free version might end up being used to train their next model? Possibly.
Most cloud-based LLMs use encryption during transmission, but data at rest might not be fully protected unless the service gurantees E2EE (End to end encryption).
Data breaches, insider access, or legal requests could compromise cloud-stored data. For sensitive work, public LLMs pose a risk unless paired with anonymization (Example: removing identifiable info) or a purchasing privacy-focused plan.
If you run an LLM locally (Example: using an open source model with quantization such as what I use, Ramzal Chat). Your data stays on your device, offering higher security. This eliminates reliance on external servers, but requires technical knowledge.
For maximum security, use a locally hosted model or a paid service with explicit data protection. Always assume public platforms aren't fully secure for confidential or sensitive data and verify their terms and conditions.
How do I use it? Simple.
How do I use it effectively? Here we go.
Here are some tips and tricks I've learned to leverage AI more effectively.
Be Specific with Prompts: Provide clear, detailed instructions to get more accurate and relevant responses. Avoid vague queries, give the model something to work with as a baseline. (Example: Re-write this 500-word article in 3 sentences.)
Break Down Complex Tasks: Split multi-step requests into smaller parts. First outline your idea, then write. Think logically. Instead of saying "Write a 1000-word essay on automation in manufacturing", start off by asking "Provide 5 key reasons to use automation in manufacturing" then perhaps you can "Ask it to analyze the reasons and break them down" then finally "Combine those ideas into a 1000-word essay on automation in manufacturing". This helps ensure data accuracy and keeps the structure coherent while also being mindful of token limitations you may experience on some models.
Use Contextual Anchors: Repat key phrases early in the prompt "Focus on the important of automation in manufacturing" to anchor the attention to that theme. Making sure your argument comes across as the focal point.
Iterate with Feedback: After each step, review the output and refine the next prompt (Example: Expand on your second point with more detail.)
Role-playing Enhances Focus: Think of your audience? Who is this for? What are you trying to gain? In our example, you may want to start off by telling the model to act as a manufacturing automations expert. This signals the model to prioritize technical knowledge and terminology. This can filter out generic responses and tailor it more towards professionals who understand the topic at hand.
Recursive Refinement: Ask the model to "check its own work" by saying things like "Review your response and suggest improvements." This mimics a peer-review process to polish results.
Simulated Dialogue: Frame the interaction as a conversation with a character (Example: "You’re a 19th-century inventor; how would you approach AI?") to unlock creative or historical perspectives it might not offer otherwise.
VERIFY: Always always always verify the data output by an LLM. Always treat LLM output as a starting point, not a definitive source. LLMs are capable of hallucination, causing them to generate plausible, but incorrect information, due to their reliance on patterns rather than real-time facts.
LLMs offer transformative potential provided it is understood and used with care.
Whew, okay. You should now have a brief understanding of what an "AI" is, is it safe, and some tips to maximize your AI usage before your next board meeting or C-Level teams meeting. I hope.
By leveraging clear prompts and iterative refinement, users can maximize its benefits while mitigating risks such as hallucinated outputs.
As AI continues to evolve, staying informed and critically verifying its results will help you make the most of this powerful tool.